Software Development
I have over five years experience of developing software. This section outlines my programming experience and the various roles I have undertaken as a software developer. This is explained in the context of the private and open-source sectors.
Outline your programming experience. What operating systems, development environments, languages are you familiar with?
This section outlines my programming experience, summarising the operating systems, programming languages and development environments that I have used during the course of my career. For an historic overview of my software development career, including the various roles and levels that I have undertaken, please refer to my answer on the various roles I have had in the development of software products.
Operating systems
I am currently a user of Ubuntu Desktop 16.04 LTS and MacOS Monetary 12.6.1 operating systems. In both cases, I typically develop using Vim, PyCharm(Community Edition) and Visual Studio Code. This is coupled with use of OpenZsh and Bash shells. I have personal experience of writing shell scripts, configuring command aliases and updating system paths etc. Please refer to this video that demonstrates an installation script for Linux software that I developed. Furthermore, I have also written a blog that gives an overview of various linux administration tasks, such as setting up SSH, CUPS etc. Please take a moment to read through the various articles on my blog site.
Programming Languages
I am predominately a mid/senior Python 3.10 software developer with experience of developing RESTful APIs using FastAPI, Django and Pyramid web frameworks, to serve and maintain resources stored within a PostgreSQL database. I have developed with Python for a variety of business domains, including: the finance, property and education sectors. I have also developed an API within the bitcoin sector using Strawberry GraphQL. This provided functionality for bitcoin investors to track price fluctuations in their investment portfolios, for a variety of exchanges.
My Python software development history encompasses the following toolsets:
- Poetry for project and dependency management.
- Black and Flake8 to format, style and lint source code.
- Pre-commit hooks to automate formatting and linting of code.
- Pytest and Behave for unit, integration and end-to-end testing.
- Mypy to perform static type checking. I prefer to use type hints with Python, to increase the readability of code.
- SQLAlchemy ORM.
- Database migrations using Go Migrate and Alembic.
- Markdown for readme documentation. This documentation details how to setup the Python virtual environment and install dependencies. Additionally, I have documented an overview of environmental configuration variables, where applicable.
- Makefiles to facilitate frequent tasks, such as: building docker images, starting/stopping docker compose stacks, running tests etc.
My public Gitlab repository highlights some exposure to React and tools/frameworks for front-end development, using Typescript and Javascript. These include: Jest, Enzyme, React-Testing-Library, Cypress and Es-Lint. This is evidenced by the research and implementation of a React front-end component that renders HTTP request errors, logged in a Redux store. Please take a moment to visit the public source code repository.
Other personal development projects include:
- Enhanced Shinobi Tensorflow plugin to despatch webcam object detections to an MQTT Mosquitto broker. I implemented a Gitlab CI pipeline to build, test and deploy an NPM package to a private Bytesafe registry.
- Blazor Server ASP.NET Core 3.1 web architecture to display object detection snapshot images, captured from live camera stream(s).
- Ruby Gem for validating Gitlab CI pipeline files. The gem is available at ruby gems.org.
Development environments
I have over three years experience of building docker images and using docker-compose, to provide local replicable development environments. This incorporates building docker images for external dependencies, such as PostgreSQL databases and message queues.
I have predominately developed using agile process models. During my career, I have collaborated and developed over two and three week sprint cycles. This has been within teams of four to five developers. Subsequently, I have designed and implemented CI/CD pipelines, coupled with Gitflow and GitHub-flow branching strategies. These pipelines have typically included stages for linting, building python packages, running tests and releasing a docker image into a private docker container registry.
My development experience has been documenting and deploying micro-services into Kubernetes clusters, typically Google Cloud Platform (GCP) or Microsoft Azure (AKS). This has been achieved using a Terraform infrastructure, created and maintained by the dev-ops team. I have deployed into a staging cluster to enable quality assurance to be performed by members of the product team. After quality assurance testing has been passed, I have deployed the software into a production environment. In all cases, deployment has involved configuring environment variables such as API base URLs, database host and ports etc.
What roles have you had in the development of software products? Which roles have you particularly enjoyed, and why?
With over five years experience as a software developer, I have worked as an active member of software development teams, implementing high quality solutions in compliance with company defined processes and life cycles. During this time, I have performed full lifecycle roles of analysis, documentation, development, implementation, testing and maintenance. Furthermore, I have also performed mentoring and participated on interview panels for recruiting and onboarding staff.
My CV highlights close collaboration with staff at all levels to implement, co-ordinate, document, test and schedule releases for deployment. I have documented APIs, SDKs, user guides and explanatory material. Furthermore, I have implemented feature enhancements and bug fixes, scheduled for release. A brief overview of my employment history demonstrates these skills in startup, financial and youth offender case management domains. The remainder of this answer gives a brief appraisal of my career history, with respect to software development roles at varying levels.
Since May 2023 I am employed at Tyk (an open-source API Gateway provider) as a Developer Experience (DX) engineer and technical author. During this time I have developed the following features:
- A proof of concept Tyk Python gRPC server, approved and published in the Tyk demo repository as an asset for supporting global commercial clients.
- A Python script, deployed as a CI error check GitHub action to report instances where new content is unassigned to the navigation menu in the documentation website.
- To assist automating the generation of change logs, I developed a Python script that generates markdown content from a CSV file.
Prior to Tyk, I was employed at WayhomeUK as a Python software engineer, responsible for developing the products, tooling and infrastructure the business needed to grow from startup. This involved developing, testing and maintaining Rest APIs in a service-oriented architecture, using FastAPI, aioHTTP, Pytest and Behave, with deployments released to a Kubernetes cluster and PostgreSQL database. I actively participated in daily sprint meetings, reporting to the product team with respect to the progress of Jira tickets over a three week sprint cycle. During this period, I was responsible for producing a range of documentation. This included:
- API reference documentation using FastAPI swagger tools.
- Explanatory guide for how to install and configure ACTICO to automate and support the credit decisioning process.
- Explanatory guides for how to configure and setup micro-services that I had created and/or maintained. This included environment variables such as database host and port, API base URL etc.
Previously, I held the role of senior full-stack developer at Business and Decision, working within a team of five to maintain the Mi-Case UK ASP.NET website for up to thirty clients within the UK. I was responsible for the full stack development and testing of new features and bug fixes. During this period the company was awarded a $12.5 million contract to deliver the Mi-Case website to USA, Maryland.
At Newcastle Building Society I was a senior Microsoft .NET analyst/developer. I worked within a team of five developers to enhance the system architecture for performing fraud detection and bank reconciliation of 1.5+ million prepaid cards issued by the company. As an active team member, I contributed to the full life cycle development of a project that migrated the legacy application to a .NET service-oriented architecture in compliance with quality control standards defined by the company and Financial Services Authority (FSA). I collaborated with both international card providers and the internal finance team, to design and document a standardised data feed specification for importing card transactions into a SQL Server database. This enhanced the robustness and dependability of the existing business workflow to allow automated collection and storage of card transactions. Furthermore, I produced user guides and conducted demonstrations for users and management at all levels. These explained usage and included tutorials.
Software development encompasses a variety of roles from requirements analysis, documentation, design and development, testing, dev-ops etc. I have given a brief overview of my career where I have performed these roles at mid and senior level.
While I do enjoy all aspects of the art of developing software, I like the creative aspects of requirements analysis, documentation, design and development. This is because I thrive when collaborating with my peers, at all levels, for identifying key functionality and assimilating information from business documents. Subsequently, I like brainstorming issues and developing solutions. I enjoy performing these at a senior level, to have an impact on the development of software. This includes establishing and documenting software architectures, CI/CD pipelines and coding style guides.
I see this an iterative process that continually evolves, reflecting on feedback from users and technical support, to update the software product for an enhanced user experience. Documentation is a key aspect that should be integrated within this process as software inevitably evolves. This facilitates management, configuration and understanding of the software product for a variety of audiences.
Outline any knowledge and experience you have of: large-scale operations, SAAS, DevOps practices; public cloud services and operations; enterprise infrastructure and application management and deployment; Linux operating systems. Ubuntu/Debian
During the course of my career I have over five years experience of developing service-oriented architectures. This involved decomposing applications into RESTful HTTP and GraphQL services. Each service has an independent data store and communicates inter-dependently using HTTP or an event bus.
An example of my knowledge and experience can be drawn from my recent employment at WayhomeUK. I was responsible for designing, developing, testing, managing and maintaining Python FastAPI and aioHTTP micro-services that were served within a Kubernetes cluster. Clusters were hosted in Google Cloud Platform (GCP) for development and production environments. Information was held within a PostgreSQL database for maintaining applications and credit records for customers seeking rental properties. Micro-services inter-dependently communicated via a Google Pub/Sub event bus. For example, the customer service published a registration event to trigger creation of a credit application record within the credit service.
I was responsible for credit decisioning and property search micro services. These were deployed within Google Cloud Platform (GCP) Kubernetes clusters for development and production environments. Each environment also contained a PostgreSQL database instance and a docker container registry. An overview of the system architecture is illustrated below.
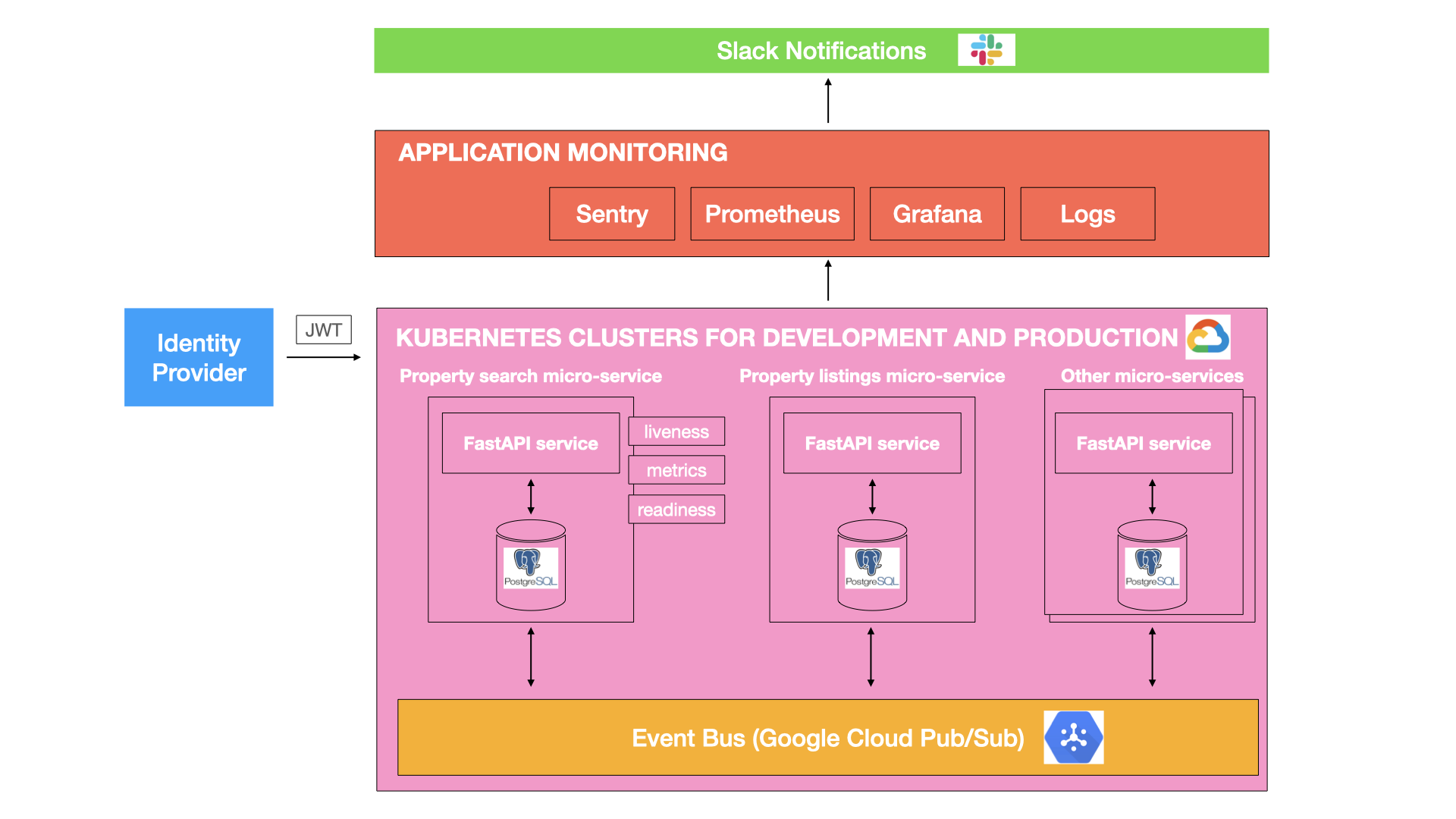
As a specific example, I created and maintained FastAPI micro-services that allowed the front-end website to maintain a series of property searches with filters for number of bedrooms, number of bathrooms etc. These were then matched with suitable property listings via an additional separate refactored service.
The remainder of this section documents my knowledge and experience during this time, with respect to the following:
- Local application development environment.
- Management of software development.
- Application monitoring and management.
- Enterprise infrastructure and deployment.
- Knowledge and experience with Linux distributions.
Local application development environment
Within each micro-service repository that I was responsible for, I created and implemented a docker infrastructure to provide a replicable development environment. This included a docker file to build a docker image of the micro-service, for use within Kubernetes clusters. I also setup a docker-compose stack to reference docker images for external application dependencies, e.g. application databases and peer micro-services. This provided opportunity for local integration and end-to-end testing.
To encourage a consistent programming style I created pre-commit hooks for linting and formatting source code when committed locally.
Local development operations were supported via a Makefile. These included make commands for: installation, building docker images, starting up and stopping the docker-compose stack, running unit and integration tests, linting etc. I documented an architecture overview, setup guides, configuration variables and Makefile usage within the repository readme file.
Management of software development
I created a GitHub repository and established a Gitflow branching strategy to manage source code for development and production environments. The pipeline contained stages for performing linting, building the Python package and running unit/integration tests with PyTest and Behave. CI tests ran against a PostgreSQL database, pulled from a private docker container registry. A branch was created for each feature implementation and underwent a code review process via GitHub pull requests. This included a CI/CD pipeline that I setup using GitHub actions, as illustrated below.
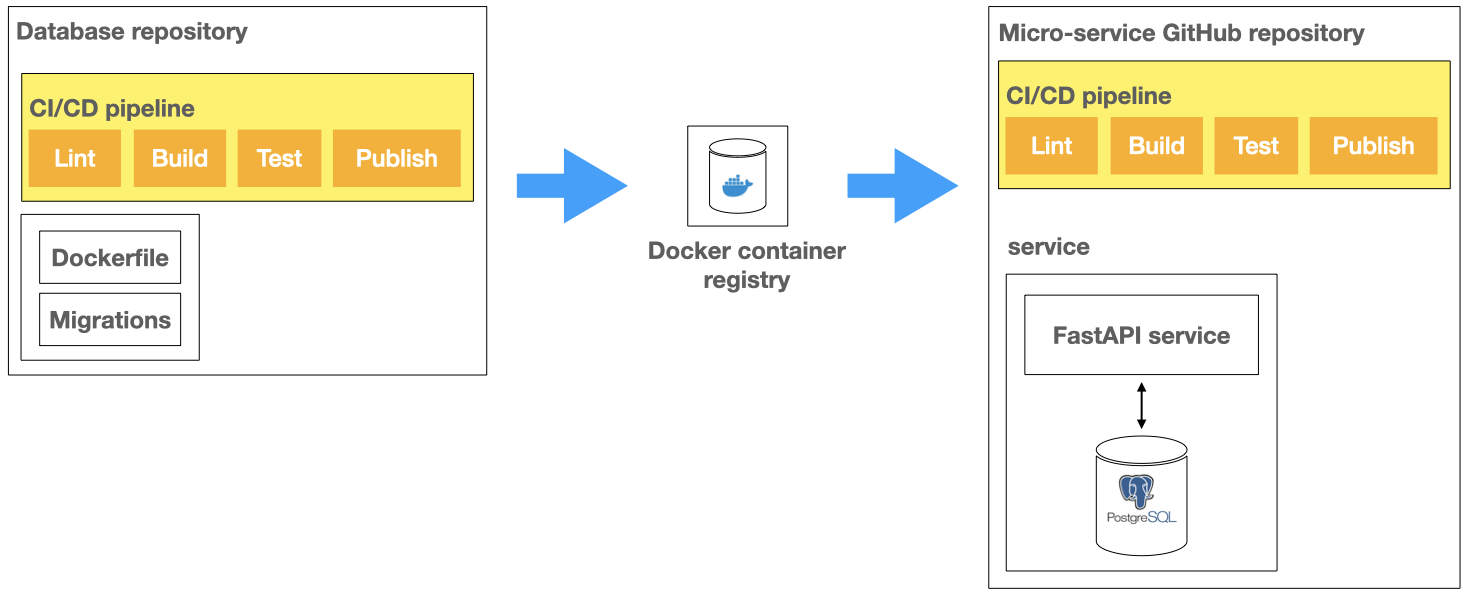
Upon approval, I would merge into the development branch to trigger running the CI/CD pipeline. This would build a micro-service docker image and publish it into a private docker container registry. At this point, I would deploy into a development staging cluster for a member of the product team to perform scheduled quality assurance. Upon approval, I would merge into the master branch. The resulting docker image built from the merge would then be ready for deployment into the production cluster. Furthermore, I would backup the production database, held in Google Cloud Platform (GCP), before applying database migrations.
Application monitoring and management
The dev-ops team setup Prometheus servers and Grafana dashboards for monitoring and visualising metrics for the organisation’s micro-services. This enabled performance monitoring and evaluation, such as: memory usage, disk space, CPU usage, server requests, total logins and total registrations. As a developer I was responsible for configuring an endpoint to enable scraping of metrics that I instrumented within the source code.
Sentry was used to monitor and report exceptions raised by micro-services within the organisation. Alert notifications were raised in the corresponding slack channels for development and production environments. This enabled the team to quickly monitor micro-services and take remedial action in the event of failure or abnormal behaviour. When developing, I used the Python Sentry SDK to capture and tag error messages and exceptions. These were monitored within the Sentry dashboard.
During development, I logged error messages, metrics and associated non-sensitive application state to assist with debugging and traceability. In the event of abnormal behaviour or failure, I used the Kubernetes kubectl utility to inspect application logs. Furthermore, I found the logs explorer dashboard of Google Cloud Platform (GCP) useful to setup queries and filters for application logs.
Finally, I implemented a health and readiness endpoint for each micro-service that I implemented. This enabled the Kubernetes cluster to diagnose the liveness and availability of pods for accepting traffic.
Enterprise infrastructure and deployment
The dev-ops team managed and maintained a separate repository to represent the infrastructure as code. This contained declarative Terraform modules for the Kubernetes cluster components and resources. These were specified for each micro-service and worker process within the organisation. Example components include: services, jobs, ingresses, secrets and security credentials for micro-services, worker processes and databases within the organisation. At a lower level, these were dynamical generated and represented as helm charts with accompanying deployment specifications, replica sets, and restart policies. Developers could configure semantic versions, tags, total replicas, memory and CPU usage for each micro-service, within a values.yaml file.
Deployment initially involved issuing a terraform apply command for the relevant development or production cluster. Deployment used the micro-service docker image from the verified merge commit or release git tag. This later progressed, when the organisation adopted the use of ArgoCD to trigger deployment into the appropriate Kubernetes cluster.
Developers would receive a notification via slack alert channels if the deployment for production and development environments failed. As a developer, I was responsible for fixing deployment errors by inspecting pod logs via the Kubernetes kubectl command line utility.
Knowledge and experience with Linux distributions
I have installed and configured Ubuntu LTS 16.04 Desktop on an Intel NUC PC. Additionally, I have also setup Arch Linux on a Raspberry Pi model A.
An overview of my Linux experience can be found at my Wordpress blog where I have documented my knowledge and experience of:
- Configuring the Raspberry Pi to share a Linux internet connection
- Configuring CUPS for Kerberos authentication
- Useful LDAP commands
I have used Ubuntu Linux for Python development. Subsequently, I am familiar with using the apt package manager to update packages and install supporting development tools such as: Python, git, docker, docker-compose, Vim and associated Vim development plugins.
Furthermore, I have used Bash and OpenZsh shells to customise my login profile, configuring aliases and appending commands to the system path.
I also have experience of installing and configuring UbuntuServer 20.04. This was for a personal development project, to host a Tensorflow application that I designed and developed to detect objects within my webcam stream. For future reference, I documented how I compiled libtensorflow for CPU optimisation with compatibility for an Intel Core 2 Q6600 @ 2.40GHz CPU. Please take a moment to visit the link for further details.
Describe any experience you have working in open-source software development.
I have over five years experience as a backend software developer. This includes implementing products using agile process models. During this time, I have contributed code to private repositories within remotely distributed teams, using GitHub and GitLab. While I have not directly contributed code to open-source repositories, I do have considerable experience with the toolset and infrastructure. This includes:
- Usage of git.
- Using Gitflow and GitHub flow branching strategies.
- Usage of slack and video conferencing tools (Google Meet and Zoom) to communicate with my peers. This includes using huddles for direct synchronous communication. Furthermore, I have also used slack channels to asynchronously communicate with my colleagues for a variety of topics, including: deployment, responding to system alerts, co-ordinating releases and scheduling demonstrations etc.
- Using GitHub issues and Jira to document, track and triage bugs for each sprint cycle.
- Design and implement CI/CD pipelines using GitHub actions and GitLab CI.
- Issue pull requests for code review.
- Perform code reviews for my peers.